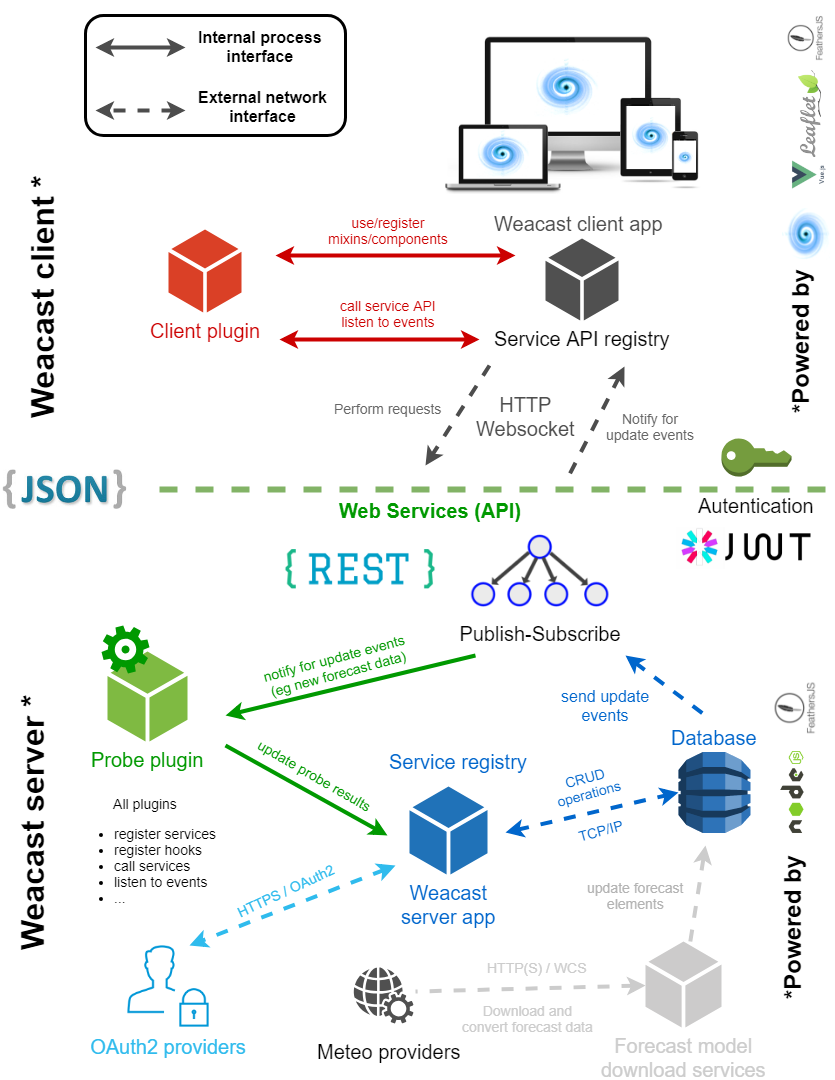
Global architecture
The typical global architecture and the underlying technologies of Weacast are summarized in the following diagram:
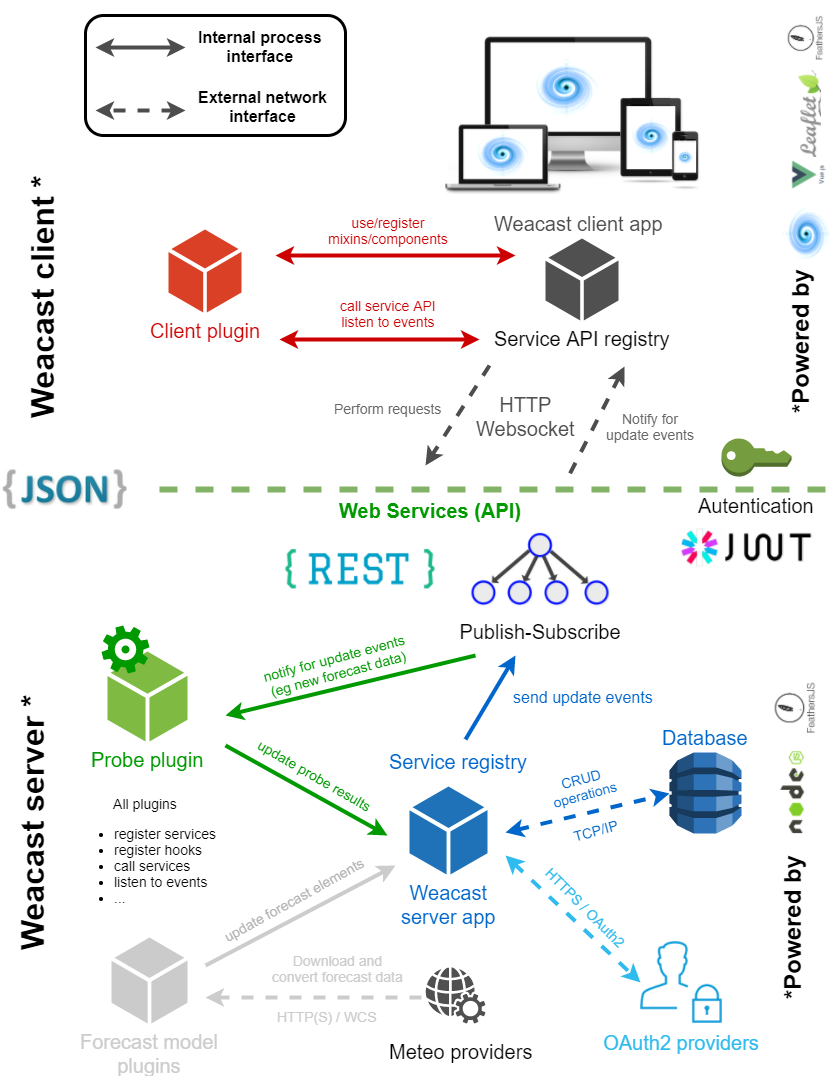
Typically, the Docker image of our demo app is actually the backend API module, configured with local forecast model plugins and serving the client demo app.
Architecture at scale
Although the typical architecture presented previously can be deployed in a single-server environment Weacast has been developed as a loosely coupled set of modules to prevent it being a monolithic piece of software. The built-in service layer helps decoupling the business logic from how it is being accessed based on a simple and unambiguous interface. Weacast can thus be deployed in a microservice architectural style, which is typically used to provide high availability. The idea is to deploy different Weacast instances on different logical hosts (can be physical machines as well as containers or virtual machines) each running a different forecast model or the probe plugin for instance. However, you will have to face some scaling configuration issues first. You also have to setup the underlying logical infrastructure. To achieve high availability, different strategies may be used.
TIP
It is recommanded to have a single source of truth (SSOT) for your data (i.e. a single database), simplifying authentication, which requires you to setup a MongoDB replica set at scale and configure the DB URL accordingly.
Monolithic application
This is the easiest strategy, you can rely on Cloud-ready solutions like Kaabah to replicate and load-balance the different instances of your application and simply use feathers-sync to synchronize service events.
TIP
This approach is something between the true monolith and the true microservices architecture, i.e. you scale your entire application but not its underlying services according to their workload.
Distributed application
You can split up your Weacast API manually on a per-responsibility basis (e.g. each forecast model on a dedicated instance) and just communicate with each other through Feathers clients using all the infrastructure that is already in place. You could also deploy a frontend application serving as an API gateway. To configure the proxy rules, edit the proxyTable option in your configuration. The frontend server is using http-proxy-middleware for proxying, so you should refer to its docs for a detailed usage but here's a simple example:
// config/default.js
module.exports = {
// ...
proxyTable: {
// proxy all requests starting with /api/service
'/api/service': {
target: 'http://my.service.com',
changeOrigin: true,
pathRewrite: {
'^/api/service': '/api'
}
}
}
}The above example will proxy the request /api/service/1 to http://my.service.com/api/1.
However, all of this requires manual work, creates a tight coupling with your underlying infrastructure and will not allow auto-scaling unless you have some discovery mechanism. You can make each instance automatically aware of others instances to distribute services and related events using feathers-distributed. This is the reason why the @weacast/api module provides you with a ready-to-go microservice backend to expose the services you'd like to using feathers-distributed by default.
Distributed forecast data processing
Because the most consuming part of a Weacast application is usually the gathering and processing of forecast model data, the weacast-loader module provides you with a set of download services available as Docker containers out-of-the-box. You can rely on Cloud-ready solutions like Kaabah to easily distribute/replicate these services on your cluster. Your Weacast application server can then only focus on forecast data retrieval for clients and can be scaled if necessary like a monolith application. The typical global architecture of such an approach is summarized in the following diagram.